Christmas gift suggestions:
- To your enemy, forgiveness;
- To an opponent, tolerance;
- To a friend, your heart;
- To a customer, service;
- To all, charity;
- To every child, a good example;
- To yourself, respect."
(by Oren Arnolds)I whish you all a merry Christmas and a really wonderful, healthy, happy and successful 2008.
by Eduardo Rodrigues
Sometime ago I had a great idea for a web application logger that would basically log events as a feed (RSS or ATOM). After a lot of thinking of the best way to implement my idea, I decided to follow the Java Logging Framework. So, basically, all I had to do was to create my own FeedHandler extending java.util.logging.Handler and also create a new java.util.logging.Formatter extension for each specific standard feed format. I started implementing RSS20Formatter based on RSS 2.0 specification. It took only 2 days for me to be completely satisfied with my own little Java Feed Logging library (which came to work really well, by the way) but then I had to make it work with my J2EE applications running in OC4J 10.1.3.x. And I wondered what would be the best way to do that. I had read OC4J’s documentation on logging and saw that it is possible to define a log handler in OC4J’s logging configuration file j2ee-logging.xml declaring its class as a subclass of java.util.logging.Handler, but that’s all the information available on how to configure OC4J loggers using the Java Logging Framework because the focus seems to be on the Oracle Diagnostic Logging Framework instead. I already use (and recommend) the ODL Framework in my J2EE applications running in OC4J mainly for its integration with web-based Oracle Enterprise Manager 10g Application Server Control Console which turns log viewing and analysis into a much more easy and comfortable experience. So, my first attempt was to add a new <log_handler> to <log_handlers> element in my j2ee-logging.xml file, basically copying my existing <log_handler> and changing its attributes and properties like that: Original j2ee-logging.xml file <?xml version = '1.0' encoding = 'iso-8859-1'?>
<logging_configuration>
<log_handlers>
<log_handler name="contaweb-handler"
class="oracle.core.ojdl.logging.ODLHandlerFactory"
formatter="oracle.core.ojdl.logging.ODLTextFormatter">
<property name="path"
value="../application-deployments/log/ContaWeb"/>
<property name="maxFileSize" value="10485760"/>
<property name="maxLogSize" value="104857600"/>
<property name="encoding" value="ISO-8859-1"/>
<property name="useSourceClassAndMethod" value="true"/>
<property name="supplementalAttributes"
value="J2EE_APP.name,J2EE_MODULE.name"/>
</log_handler>
</log_handlers>
<loggers>
<logger name="tim.contaweb" level="ALL" useParentHandlers="false">
<handler name="contaweb-handler"/>
</logger>
</loggers>
</logging_configuration>New j2ee-logging.xml file <?xml version = '1.0' encoding = 'iso-8859-1'?>
<logging_configuration>
<log_handlers>
<log_handler name="contaweb-handler"
class="oracle.core.ojdl.logging.ODLHandlerFactory"
formatter="oracle.core.ojdl.logging.ODLTextFormatter">
<property name="path"
value="../application-deployments/log/ContaWeb"/>
<property name="maxFileSize" value="10485760"/>
<property name="maxLogSize" value="104857600"/>
<property name="encoding" value="ISO-8859-1"/>
<property name="useSourceClassAndMethod" value="true"/>
<property name="supplementalAttributes"
value="J2EE_APP.name,J2EE_MODULE.name"/>
</log_handler>
<log_handler name="contaweb-rss-handler"
class="oracle.br.logging.feed.FeedHandler"
formatter="oracle.br.logging.feed.RSS20Formatter">
<property name="path" value="../applications/ContaWeb/ContaWeb/rss"/>
<property name="level" value="INFO"/>
<property name="title" value="ContaWeb Log Events"/>
<property name="link" value="http://localhost:8888/em/"/>
<property name="limit" value="100"/>
</log_handler>
</log_handlers>
<loggers>
<logger name="tim.contaweb" level="ALL" useParentHandlers="false">
<handler name="contaweb-handler"/>
<handler name="contaweb-rss-handler"/>
</logger>
</loggers>
</logging_configuration>Note that I just added my new log handler to my existing logger named “tim.contaweb” which was already used by my application. In other words, every single log event generated by this logger will be directed to both handlers in a transparent way. The problem was it didn’t work at all :(((( Making the long story short, after googling a lot, I first found that the <property> elements and the “formatter” attribute in a <log_handler> are effective only if its class is oracle.core.ojdl.logging.ODLHandlerFactory. Then I also found that my answer was inside the ODL JAR file (ojdl.jar): the logging configuration DTD/Schema. If you look inside ojdl.jar (which is generally located at $ORACLE_HOME/diagnostics/lib) you’ll find files oracle.core.ojdl.logging.logging-config.dtd and oracle.core.ojdl.logging.logging-config.xsd and, after examining them, you’ll notice the non-documented element <logging_properties> which is the first optional element inside the root element <logging_configuration>. In fact, this <logging_properties> only takes <property name=”” value””/> elements and has the exact same behavior as those properties declared in file $JAVA_HOME/jre/lib/logging.properties, and those are the ones needed by Java Logging Framework. So, my working j2ee-logging.xml file is: <?xml version = '1.0' encoding = 'iso-8859-1'?>
<logging_configuration>
<logging_properties>
<property name="oracle.br.logging.feed.FeedHandler.formatter"
value="oracle.br.logging.feed.RSS20Formatter"/>
<property name="oracle.br.logging.feed.FeedHandler.path"
value="../applications/ContaWeb/ContaWeb/rss"/>
<property name="oracle.br.logging.feed.FeedHandler.level"
value="INFO"/>
<property name="oracle.br.logging.feed.FeedHandler.title"
value="ContaWeb Log Events"/>
<property name="oracle.br.logging.feed.FeedHandler.link"
value="http://localhost:8888/em/"/>
<property name="oracle.br.logging.feed.FeedHandler.limit"
value="100"/>
</logging_properties>
<log_handlers>
<log_handler name="contaweb-handler"
class="oracle.core.ojdl.logging.ODLHandlerFactory"
formatter="oracle.core.ojdl.logging.ODLTextFormatter">
<property name="path"
value="../application-deployments/log/ContaWeb"/>
<property name="maxFileSize" value="10485760"/>
<property name="maxLogSize" value="104857600"/>
<property name="encoding" value="ISO-8859-1"/>
<property name="useSourceClassAndMethod" value="true"/>
<property name="supplementalAttributes"
value="J2EE_APP.name,J2EE_MODULE.name"/>
</log_handler>
<log_handler name="contaweb-rss-handler"
class="oracle.br.logging.feed.FeedHandler"/>
</log_handlers>
<loggers>
<logger name="tim.contaweb" level="ALL" useParentHandlers="false">
<handler name="contaweb-handler"/>
<handler name="contaweb-rss-handler"/>
</logger>
</loggers>
</logging_configuration>It’s also very important to say that all log handlers declared in file j2ee-loggin.xml will be automatically instantiated during OC4J’s startup process. Because of this, all needed classes must be reachable from OC4J’s boot class loader. There were some options to achieve that but, in my case, the easiest was to deploy my new logging library to a JAR file and just put it in $ORACLE_HOME/j2ee/home/lib/ext directory. That’s all for now. I hope it’s useful.
by Eduardo Rodrigues
Yes. The title of this post really is SQLDeveloper. I did not write it wrong. But what it has to do with Java? Well, the answer is simple: Oracle SQLDeveloper is a very useful and interesting database tool for developers and is build in Java. It's like an IDE for Oracle DB and has somethings in common with JDeveloper. For those who are now curious, Oracle SQLDeveloper may be downloaded from Oracle Technology Network. I use it and certainly recommend it for developers (not for DBAs). With all that said, let's go directly to the point... One of the things SQLDeveloper has in common with JDeveloper is how its setup is done. However, in it's latest versions (1.2.1 was the latest version at the time this post was written), SQLDeveloper has a small setup trick. As you will notice, SQLDeveloper does not come with an installer program. All you have to do is uncompress the downloaded zip archive and run sqldeveloper.exe located in its root directory. You may choose to download it with a bundled JDK 1.5.0_06 or without it and then set it up to use a more recent JDK (version 6 is already certified). Looking inside the expanded directory tree, you'll find an "<SQLDeveloper_Install_Dir>/SQLDeveloper/bin" subdirectory containing the files "sqldeveloper.conf" and "jdk.conf". The former is the setup starting point and the latter is empty when you download SQLDev without the bundled JDK. Edit this file and notice the "IncludeConfFile" directives. The first one points to an "ide.conf" file located in "<SQLDeveloper_Install_Dir>/jdev/bin" subdirectory. This file works for SQLDev much like "jdev.conf" does for JDev. Some important things you may setup there is Java Heap maximum size and, specially for Windows users, the keepWorkingSetOnMinimize system property which avoids SQLDev's working memory to be paged out by Windows when you minimize it (believe me, you want this system property set). You may set those like this:
# setting maximum heap to 256 MB
AddVMOption -Xmx256M
#setting keepWorkingSetOnMinimize
AddVMOption -Dsun.awt.keepWorkingSetOnMinimize=true
If you look at the same subdirectory, you'll find another "jdk.conf" file, this time with the following content:
###############################################################
# Oracle IDE JDK Configuration File
# Copyright 2000-2006 Oracle Corporation.
# All Rights Reserved.
###############################################################
#
# Directive SetJavaHome is not required by default,
# except for the base install, since the launcher will
# determine the JAVA_HOME. On Windows it looks
# in ..\..\jdk, on UNIX it first looks in ../../jdk.
# If no JDK is found there, it looks in the PATH.
#
# SetJavaHome C:\Java\jdk1.5.0_04
Because SetJavaHome directive is commented out, this file has pretty much the same effect as the empty one located in "<SQLDeveloper_Install_Dir>/SQLDeveloper/bin" subdirectory. In this case, the application will look for the bundled Java Runtime Engine which should be located in "<SQLDeveloper_Install_Dir>/jdk" subdirectory. And this is the trick. Which of the "jdk.conf" files is the correct one? The answer is: the empty "jdk.conf" in "<SQLDeveloper_Install_Dir>/SQLDeveloper/bin" subdirectory. So, if want or need to specify what JDK should be used to run SQLDeveloper, you must edit this file and add the following:
# tipical setting for Windows
# (you don't need to enclose the path with double quotes)
SetJavaHome C:\Program Files\Java\jdk1.5.0_12
In order to confirm your settings, just open the "About" window and select the "Version" tab: There you may check what Java is being used and, looking at the "Properties" tab, you may check all other settings. That's it. Best regards to all!
by Eduardo Rodrigues
Continuing from my last post about some lessons learned at JavaOne'07 on Java performance since JDK 1.5, there's something we usually do not pay much attention to but which can get us some trouble: object finalizers. Every time we override the protected void finalize() throws Throwable method, we are implicitly creating a postmortem hook to be called by the Garbage Collector after it finds that the object is unreachable and before it actually reclaims the object's memory space. In general, we override finalize() with the best of the intentions which is to ensure that all necessary disposal of system resources and any other cleanup will be performed before the object is permanently discarded. So why is that an issue? Well, we all should know that finalize() is an empty method declared in java.lang.Object class, therefore, inherited by any existing Java class. So, when it's overridden, the JVM can't assume the default trivial finalization for the object anymore which means that "fast allocation" won't happen here. In fact, "finalizable" objects have much slower allocation simply because the VM must keep track of all finalize() hooks. Besides, those objects also give much more work to the GC. It takes at least 2 GC cycles (which are also slower) to reclaim a "finalizable" object. The first is the usual one when the GC identifies the object as garbage. The difference is that now it has to enqueue the object on finalization queue. Only during a next cycle GC will dequeue and call the object's finalize() method and, if we're lucky, discard the object and reclaim its space, or else, it may take another cycle just to finally get rid of that object. If we look closer, we'll notice that putting more pressure on the GC and slowing down both initialization and finalization processes are not the only problems here. Let's take a quick look at the J2SE 5.0 API Javadoc for the Object.finalize() method: " (...) After the finalize method has been invoked for an object, no further action is taken until the Java virtual machine has again determined that there is no longer any means by which this object can be accessed by any thread that has not yet died, including possible actions by other objects or classes which are ready to be finalized, at which point the object may be discarded. The finalize method is never invoked more than once by a Java virtual machine for any given object. Any exception thrown by the finalize method causes the finalization of this object to be halted (...)" It is quite clear to me that there's a potential temporary (or even permanent) " memory leak" matter hidden in that piece of Javadoc. Since the JVM is obligated to execute the finalize() method before discarding any object overriding it, in fact, due to the additional GC cycles described above, not only that specific object will be retained longer in the heap but also any other objects that are still reachable from it. In the other hand, even after executing finalize(), the VM will not reclaim an object's space if, by any means, it may still be accessed by any object or class, in any living thread, even if they're also ready to be finalized. Like it isn't enough, if any exception is thrown uncaught during finalize() execution, the finalization of the object is halted and there's a good chance that, in this case, this object will be retained forever as garbage. At last, the fact that the finalize() method should never be invoked more that once for any given object certainly implies the use of synchronization which is one more performance threatening element. So, next time you consider writing a finalizer in a class, please, take a second look at it. And if you really have to do that, be really careful with the code you write and try to follow these tips: - Use finalizers only as a last resort!
- Even if you do not explicitly override the finalize() method, library classes you extend may have done it. Look at the example bellow:
class MyFrame extends JFrame {
private byte[] buffer = new byte[16*1024*1024];
(...)
}
In JDK 1.5 and earlier, the 16MB buffer will survive, at least, 2 GC cycles before any MyFrame instance is discarded. That's because JFrame library class does declare a finalizer. So, try to split objects in cases like this:
class MyFrame {
private JFrame frame;
private byte[] buffer = new byte[16*1024*1024];
(...)
}
- Even if you're considering to use a finalizer to dispose expensive and scarce resources, keep in mind that, being scarce, it's very likely that they will be exhausted before memory (assuming that memory is usually plentiful). So, in these cases, prefer to pool scarce resources instead.
To be continued...
I've being trying to solve this issue for a long time. I've read many blogs, forums and articles about it but, none was a complete solution. Fortunately, now that I've finally managed to put it all together I decided to share with you all.
The problem is very simple and, as far as I noticed, very common also. I want to build a combo box based on a result set from my database within an ADF Faces page. Ok, I know, I should use the selectOneChoice component bound to my database through a PageDefinition XML. What if I also need to bind a specific attribute from my result set to the value attribute of each item in the selectOneChoice component? Well, believe me... it's not as easy as it may seem.
By definition, when a bound selectItems tag is used with the seleceOneChoice component, ADF will render each item like this:
<option value="N">bound resultset attribute as the option label</option>
"N" being a natural number varying from 0 (zero) to the total number of rows in the result set minus 1. In other words, an item's value will always be the index of it's corresponding row in the bound iterator's collection, no matter what. The problem is that, many times, it's really important to have more meaningful information as the item's value, specially when we need to make some client-side processing based on it. The question is: how? Well, here is the complete answer with very simple example.
Suppose we've defined a list binding identified by "myList" bound to an iterator for a collection of objects of the following bean class:
public final class ListItemBean {
private String itemValue;
private String itemLabel;
public ListItemBean() {}
public void setItemValue(String value) {
this.itemValue = value;
}
public void setItemLabel(String label) {
this.itemLabel = label;
}
public String getItemValue() {
return this.itemValue;
}
public String getItemLabel() {
return this.itemLabel;
}
}
The most common use case of <af:seleconechoice> would be:
<af:selectonechoice id="myCombo" value="#{bindings.myList.inputValue}">
<f:selectitems value="#{bindings.myList.items}"/>
</f:selectitems>
The label of each will be rendered according to myList definition in the PageDefinition XML file. So, if I want to use the bean attribute itemLabel, myList definition should be something like this:
<list listopermode="1" iterbinding="myListIterator" id="myList">
<attrnames>
<item value="itemLabel">
</item>
</attrnames>
Now, if I want to take control of how each will be rendered:
<af:selectonechoice id="myCombo" valuepassthru="true" value="#{bindings.myList.inputValue}">
<af:foreach items="#{bindings.myList.iteratorBinding.allRowsInRange}" var="row">
<af:selectItem id="myItem"
value="#{row.dataProvider.itemValue}"
label="#{row.dataProvider.itemLabel}"/>
</af:forEach>
</af:selectOneChoice>
It is very important to define an id for af:selectitem. If you don't, ADF runtime won't render the page correctly. Also notice the valuePassThru attribute defined to "true". It tells ADF to render each selectItem like this: <option value="the item's real value goes here">the item's label goes he</option>. That's important exactly because I need to make client-side processing using items real values. Without valuePassThru="true", the options values would continue to be rendered as corresponding indexes. Before you ask, know that simply adding valuePassThru="true" to the common use case above won't work since ADF ignores it if you aren't using af:selectItem.
Well, that should be all, but it isn't. There's one side effect which is a potentially unwanted empty element as your combo box's first option. That's because now, ADF doesn't have a default value for your combo box when it's first rendered. There are many different ways of solving this minor issue but, in my opinion, the easiest would be to add the following JavaScript to the page:
<script type="text/javascript">
function removeEmptyOption() {
if (document.forms[0].myCombo.options[0].value=='') {
document.forms[0].myCombo.options[0] = null;
document.forms[0].myCombo.value = document.forms[0].myCombo.options[0].value;
}
}
</script>
Now, just call it from the page body's onLoad event: <afh:body onload="removeEmptyOption()">
If you prefer, you may also use CSS to do the job (which I think is far more elegant). Just add the following style to the page:
<style type="text/css" media="screen">
option[value=""] {
display: none;
}
</style>
The problem with this solution is that CSS Selectors are not compatible with all browsers, specially with IE6 : (
So, that's it. I hope you enjoy.
by Eduardo Rodrigues Hello everybody! I know I've promised more posts with my impressions on JavaOne 2007. So, here it goes... Some of the most interesting technical sessions I've attended to were on J2SE performance and monitoring. In fact, I would highlight TS-2906: "Garbage Collection-Friendly Programming" by John Coomes, Peter Kessler and Tony Printezis from the Java SE Garbage Collection Group at Sun Microsystems. They certainly gave me a new vision on the newest GCs available. And what does GC-friendly programming have to do with performance? Well, if you manage to write code that doesn't needlessly spend GC processing, you'll be implicitly avoiding major performance impacts to your application. Today there are different kinds of GCs and a variety of approaches for them too. We have generational GCs which keeps young and old objects separetely in the heap and uses specific algorithms for each generation. We also have the incremental GC which tries to minimize GC disruption working in parallel with the application. There's also the possibility of mixing both using a generational GC with the incremental approach being applied only to the old generation space. Besides, we have campacting and non-compacting GCs; copying, mark-sweep and mark-compact algorithms; linear and free lists allocation and so on. Yeah... I know... another alphabet soup. If you want to know further about them, here are some interesting resources: The first and basic question should be "how do I create work for the GC?" and the most common answers would be: allocating new memory (higher allocation rate implies more frequent GCs), "live data" size (more work to determine what's live) and reference field updates (more overhead to the application and more work for the GC, especially for generational or incremental). With that in mind, there are some helpful tips for writing GC-friendly code: - Object Allocation
In recent JVMs, object allocation is usually very cheap. It takes only 10 native instructions in fast common cases. As a matter of fact, if you think that C/C++ has faster allocation you're wrong. Reclaiming new objects is very cheap too (especially for young generation spaces in generational GCs). So, do not be affraid to allocate small objects for intermediate results and remember the following:
- GCs, in general, love small immutable objects and gerational GCs love small and short-lived ones;
- Always prefer short-lived immutable objects instead of long-lived mutable ones;
- Avoid needless allocation but keep using clearer and simpler code, with more allocations instead of more obscure code with fewer allocations.
As a simple and great example of how the tiniest details may jeopardize performance, take a look at the code bellow:
public void printVector(Vector v) {
for (int i=0; v != null && i < v.size(); i++) {
String s = (String) v.elementAt(i);
System.out.println(s.trim());
}
}
This must look like a very inocent code but almost every part of it may be optimized for performance. Let's see... First of all, using the expression "v != null && i < v.size()" as the loop condition generates a totally unecessary overhead. Also, declaring the String s inside the loop implies needless allocation and, last but not least, using System.out.println is always an efficient way of making you code really slow (and that's inside the loop!). So, we could rewrite the code like this:
public void printVector(Vector v) {
if (v != null) {
StringBuffer sb = new StringBuffer();
int size = v.size();
for (int i=0; i < size; i++) {
sb.append(((String)v.elementAt(i)).trim());
sb.append("\n");
}
System.out.print(sb);
}
}
And if we're using J2SE 1.5, we could do even better:
public void printVector(Vector<String> v) {
//using Generics to define the vector's content type
if (v != null) {
StringBuilder sb = new StringBuilder();
//faster than StringBuffer since
//it's not synchronized and thread-safety
//is not a concern here
for (String s : v) { //enhanced for loop
sb.append( s.trim() );
//we're using Generics, so
//there's no need for casting
sb.append( "\n" );
}
System.out.print(sb);
}
}
- Large Objects
Very large objects are obviously more expensive to allocate and to initalize (zeroing). Also, large objects of different sizes can cause memory fragmentation (especially if you're using a non-compacting GC). So, the message here is: always try to avoid large objects if you can.
- Reference Field Nulling
Differently of what many may think, nulling references rarely helps the GC. The exception is when you're implementing array-based data structures.
- Local Variable Nulling
This is totaly unecessary since the JIT (Just In-Time compiler) is able to do liveness analysis for itself. For example:
void foo() {
int[] array = new int[1024];
populate(array);
print(array);
//last use of array in method foo()
array = null;
//unnecessary! array is no
//longer considered live by the GC
...
}
- Explicit GCs
Avoid them at all costs! Applications does not have all the information needed to decide when a garbage colletion should take place, besides, a call to System.gc() at the wrong time can hurt performance with no benefit. That's because, at least in HotSpottm, System.gc() does a "stop-the-world" full GC. A good way of preventing this is using -XX:+DisableExplicitGC option to ignore System.gc() calls when starting the JVM.
Libraries can also make explicit System.gc() calls. An easy way to find out is to run FindBugs to check on them.
If you're using Java RMI, keep in mind that it uses System.gc() for its distributed GC algorithm, so, try to decrease its frequency and use -XX:+ExplicitGCInvokesConcurrent option when starting the JVM.
- Data Structure Sizing
Avoid frequent resizing and try to size data structures as realistically as possible. For example, the code bellow will allocate the associated array twice:
ArrayList list = new ArrayList();
list.ensureCapacity(1024);
So, the correct should be:
ArrayList list = new ArrayList(1024);
And remember... array copying operations, even when using direct memory copying methods (like System.arrayCopy() or Arrays.copyOf() in J2SE 6), should always be used carefully.
- Object Pooling
This is another old paradigm that must be broken since it brings terrible allocation performance. As you must remember from the first item above, GC loves short-lived immutable objects, not long-lived and highly mutable ones. Unused objects in pools are like bad tax since they are alive and the GC must process them. Besides, they provide no benefit because the application is not using them.
If pools are too small, you have allocations anyway. If they are too large, you have too much footprint overhead and more pressure on the GC.
Because any object pool must be thread-safe by default, the use of synchronized methods and/or blocks of code are implicit and that defeats the JVM's fast allocation mechanism.
Of course, there are some exceptions like pools of objects that are expensive to allocate and/or initialize or that represent scarse resources like threads and database connections. But even in these cases, always prefer to use existing well-known libraries.
to be continued...
by Eduardo Rodrigues Yet another great tip - this one is specially directed to those using JDeveloper on Windows. It may seem strange but the amount of programmers aware of the possibility of customizing JDev's initialization settings isn't so big as you may expect. Many don't even know about the existence of a configuration file. Well, there is a configuration file and it's located at %JDEV_HOME%\jdev\bin\jdev.conf (%JDEV_HOME% being the directory where you've installed JDeveloper). If you open this file you'll see a great number of options, properties, etc. The guys at Oracle did their job and commented on every one, so it won't be difficult to figure out their purpose. Having said that, I'd like to share with you some lessons learned through my own experience that have certainly made my work with JDeveloper much smoother:
#
# This is optional but it's always
# interesting to keep your JDK up to date
# as long you stay in version 1.5
#
SetJavaHome C:\Program Files\Java\jdk1.5.0_12
#
# Always a good idea to set your User Home
# appropriately. To do so, you must
# configure an environment variable in
# the operating system and set its value
# with the desired path
# (i.e. JDEV_USER_HOME=D:\myWork\myJDevProjs).
# Then you must set the option bellow with
# the variable's name.
#
# You'll notice that when you change
# the user home directory, JDev will ask
# you if you want to migrate from a
# previous version. That's because it
# expects to find a "system" subdirectory.
# If you don't wanna loose all your config
# I recommend that you copy the "system"
# folder from its previous location
# (%JDEV_HOME%\jdev\system is the default) to
# your new JDEV_USER_HOME before restarting
# JDev.
#
SetUserHomeVariable JDEV_USER_HOME
#
# Set VFS_ENABLE to true if your
# projects contain a large number of files.
# You should use this specially if
# you're using a versioning system.
#
AddVMOption -DVFS_ENABLE=true
#
# Try to make JDev always fit in your available
# physical memory.
# I really don't recommend setting the maximum
# heap size to less than 512M but sometimes it's
# better doing this than having to get along with
# unpleasant Windows memory swapping.
#
# Just a reminder: this option does not establish
# an upper limit for the total memory allocated
# by the JVM. It limits only the heap area.
#
AddVMOption -Xmx512M
#
# Use these options bellow ONLY IF you're
# running JDeveloper on a multi-processor or
# multi-core machine.
#
# These options are designed to optimize the pause
# time for the hotspot VM.
# These options are ignored by ojvm with an
# information message.
#
AddVMOption -XX:+UseConcMarkSweepGC
AddVMOption -XX:+UseParNewGC
AddVMOption -XX:+CMSIncrementalMode
AddVMOption -XX:+CMSIncrementalPacing
AddVMOption -XX:CMSIncrementalDutyCycleMin=0
AddVMOption -XX:CMSIncrementalDutyCycle=10
#
# On a multi-processor or multi-core machine you
# may uncomment this option in order to
# limit CPU consumption by Oracle JVM client.
#
# AddVMOption -Xsinglecpu
#
# This option isn't really documented but
# it's really cool!
# Use this to prevent Windows from paging JDev's memory
# when you minimize it.
# This option should have the same effect as
# the KeepResident plug-in with the advantage
# of being a built-in feature in Sun's JVM 5.
#
AddVMOption -Dsun.awt.keepWorkingSetOnMinimize=true
by Felippe Oliveira Hi folks! This post is directed to Oracle JDeveloper users and was originally written by Felippe Oliveira who is a consultant for Oracle Brazil. Do you have a hard time tying to figure out the best way of configuring your projects' libraries so they're truly portable? Well, the lack of an easy-to-use "environment variables" setting mechanism (like the one we may find in Eclipse) can make it even harder. So here's a userful suggestion to address this issue. Basically, the JDeveloper workspace consists of applications that are composed of projects which, in fact, contain packages, classes, resources and other files. This structure is normally reflected in the filesystem. Let's say you're working on 2 ADF applications and your local work directory is c:\mywork. The directory structure should look like this: 
The question is: where should you place your custom and/or external libraries? The best answer is as follows: Step 1: create a child subdirectory of c:\mywork and put them all there, like this: 
Step 2: back to your JDev, select "Tools -> Manage Libraries..." in the menu and click the "Load Dir..." button and select the lib directory created before. 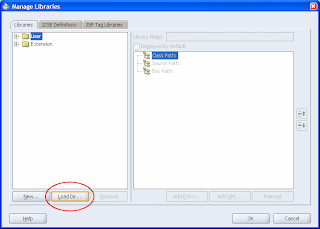
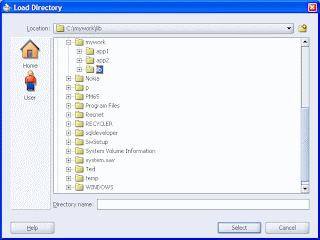
Note that a new "lib" folder will appear in the "Libraries" tab. Step 3: Click the "New..." button to create each of your new libraries, referencing the corresponding JAR or ZIP files in the c:\mywork\lib directory: 
The main advantage of doing this relies in that JDev puts one file with a ".library" extension in c:\mywork\lib for each of the libraries you've created. Plus, all paths referenced in those files will be relative to c:\mywork. Now, if you need to recreate the whole workspace in another JDev installation, all you have to do is copy c:\mywork to any other location in the destination machine and repeat step 2. This time you'll notice that all libraries will be automatically listed under the "lib" folder in the "Libraries" tab and that's it. Your libraries are ready to go! Another interesting advantage to consider is that this structure is ideal for versioning systems. Just import the entire structure under c:\mywork into the repository. Whoever checks out the same structure won't have to reconfigure all projects' libraries nor adjust them to their local directories. That's all for now. Thanks again to Felippe. Good stuff!
by Eduardo Rodrigues As promised, here goes my first summary on JavaOne 2007. The first topic will be Web 2.0. I was greatly impressed with the quality we can achieve with respect to user interfaces in web based systems nowadays. To build real world applications provided with extremely rich interfaces like GMail or Yahoo! seems not to be so difficult as one could imagine. At first, it may seem a bit scary to face the challenge of widely adopting AJAX in our projects but my feeling (which has certainly been confirmed during J1) is that we've already reached the point of no return. Web developers should already be capacitating themselves in order to be able to provide web applications with a much more modern, interactive and richer user interface. Those who choose to ignore this fact are likely to be left behind. Offering only the minimum is about to become unacceptable. Several libraries, plug-ins for the largest used IDEs (unfortunately JDeveloper is not included in that list, but that's another matter) and other stuff are emerging so fast that we must pay attention to them now or it might be more and more difficult to catch up later. I'm quite sure this is not going to be a very smooth transition. All those concepts and approaches that have being ruling our user interface design and implementation (such as very well defined life-cycles and the old comfortable synchrony) are to be brought to the ground by absolute asynchrony and an avalanche of timers and messages triggering events, etc. This new approach is the foundation of the freedom and interactivity that are bringing the web to the next level. Well, the good news for us working with Oracle JDeveloper is that Oracle is certainly aware of this process. A brand new set of ADF Faces components are coming along with JDeveloper 11g and promise to enable this great new technology in a very easy way. I'm talking about ADF Faces Rich Client which, just like ADF Faces itself, has just been donated by Oracle to the Apache foundation. For those interested in getting a taste of it, here are some links from OTN: Another thing that caught my attention was jMaki. It's a framework for web 2.0 development that seems to make the task much faster and easier. It comes with most of the main widgets libraries, like Google, Yahoo! and DOJO out of the box. jMaki was created under Java.net GlassFish community seal and, until now, there's only a NetBeans plug-in available; however, it may be used with any J2EE IDE (running JDK 5 or greater). A very interesting characteristic of this framework is the solution given to communication between widgets. It's called GLUE and uses JavaScript functions to deliver a message bus to publish/subscribe events which makes it possible for a full decoupling of the various components (or widgets) since there's no need for argument passing between them at all. It's really worth looking at: Well... I think that's enough for now. Next subject will be "JVM performance and monitoring". Best regards for all!
by Eduardo Rodrigues  One week late but... never too late. Yes! I went to JavaOne 2007. And it was great! People (lots of) from all over the world were there. The most important players, the men behind the curtains, they were all there. There were too many sessions for a single human being to attend to. So I had to filter them hoping to choose the best ones. Of course my filter wasn't very accurate all the time. I focused my interests in the following subjects: web 2.0, JVM's performance and monitoring, mobile and SOA. Of all sessions I attended (an average of 4/day), those which have enriched me the most were on web 2.0, performance and monitoring and mobile. I wasn't so lucky with the SOA sessions I chose. One was too comercial and the other was too boring. A pity because that's a subject in which I have great interest. So let's skip the bad parts and stick to the good ones...
|
|
 Switch to new Dynamic Views
Switch to new Dynamic Views









