by Fábio Souza Guys and girls, I guess the best way to start this post is with my appologies. I really wanted to post it earlier, but you all know how things are =P. It has been almost three months from when I took the SCJP 6 upgrade exam (310-056). The exam follows the same SCJP 5's (310-055) difficulty level where it's needed to pay attention to every detail. There is time enough to do everything calmly but the tricks are there like they were in SCJP 5. The "secret" is still the same: MAKE LOTS OF EXERCISES. In my case, my knowledge on 310-055 was pretty sharp and I just had to work out the new features of Java 6. Lets talk about the exam and how to go for it.
PS: To get your knowledge on 310-055 "pretty sharp", I recommend my previous post: SCJP5 and 6Technical information:- Number of Questions: 48
- Score needed: 66% (32 of 48 questions)
- Time limit: 150 minutes
Resource material:For those who don't have (or want to have) specific SCJP 6 material (the same of the previous post): For those who want to buy new material: * I've never read this book but if the quality is the same of the previous version, there is no doubt it should work.I made an abstract to help me with the SCJP 6 content by comparing the requisites for both exams (310-055 and 310-065), and studying the Java 6 new features. Here it is: - Ordered and Sorted comparison:  - NavigableSet and NavigableMap methods comparison:  - Other things: - Deque: in this interface's javadoc there is a full explanation about the different methods that can be used to add/remover an object of this queue. Be sure that you know the ones that returns an special value (generally null) or that throws an exception instead, when something goes wrong.
- ArrayDeque: the best (fastest) way to make FIFO and LIFO queues. This is also the recommended implementation when we need a Stack.
- LinkedList: choose this implementation when objects should be added/removed between the first and the last element.
- java.util.Collections: there are two new methods in this class, newSetFromMap and asLifoQueue, learn them.
- java.util.Arrays: avoid System.arraycopy, use the new methods Arrays.copyOf or Arrays.copyOfRange instead.
- java.io.File: getFreeSpace, getTotalSpace, setExecutable, setWritable, setReadable. These are new methods to learn.
- java.io.IOException: there are new constructors that enable exception chaining IOException(String,
Throwable) and IOException(Throwable).
- java.io.Console: this is a new class and its instance should be got using System.console. I think all of its methods are importants, take a look at the javadoc. Pay attention to the Console.readPassword, it will fill an array with the provided password, it is a good think to know how to clean this array. This is a good way: java.util.Arrays.fill(src, '\0') and this is a valid and bizarre way: java.util.Arrays.fill(src, 0, src.length, (char)0).
SCJP 6 - To do or not to doBecause the difference between Java 5 and Java 6 is very little, in my opinion, people who already have the SCJP 5 don't need to worry about SCJP 6. For those who don't have SCJP 5 or any SCJP certificate at all: DON'T DO the Java 5 exam; GO STRAIGHT to Java 6. In my exam (just to freeze: 310-056), the Java 6 content was kind of ridiculous. Only THREE specific questions. It means (this is not an advice) I could take the SCJP 6 exam without any knowledge about its specific content. I'll tell you how it was like: - java.io.Console: A question about its usage. It was necessary to know how to get the Console instance and how to get typed lines.
- java.util.NavigableSet and the implementation java.util.TreeSet: The question was about how to use them focusing the method subset.
- Chosing the best Collection implementation: I don't remember exactly what was asked, but keep this in mind:
- Stack or queue needed: use ArrayDeque.
- Removing/Adding elements that might not be at the top or at the bottom: LinkedList.
- Sorted Collection (unique elements): TreeSet.
That is all folks! Please send your comments, corrections and share your own experiences.
by Fábio Souza OK, I know that is a little late to talk about SCJP 5 but I will give my feedback about the exam. This will help people that feels unprepared to take SCJP 6 (that was my case) and the ones that are going to take this new version, what I know is that both exams (5 and 6) are very similar. Resources: - Main resource material: SCJP Sun Certified Programmer for Java 5 Study Guide (Exam 310-055)
 , by Katherine Sierra (Author), Bert Bates (Author). This book is just great! The authors are very careful with the explanations and they also made very good illustrations. Each chapter ends with the "Two-minute Drill" section and the exercises. The "Two-minute Drill" has an abstract about the chapter that makes very easy to review forgotten items. The exercises are very well written, and every answer is explained (both wrong and right). , by Katherine Sierra (Author), Bert Bates (Author). This book is just great! The authors are very careful with the explanations and they also made very good illustrations. Each chapter ends with the "Two-minute Drill" section and the exercises. The "Two-minute Drill" has an abstract about the chapter that makes very easy to review forgotten items. The exercises are very well written, and every answer is explained (both wrong and right).
- Main resource material for exercises: MasterExam. My SCJP Sun Certified Programmer for Java 5 Study Guide (Exam 310-055) book came with a CD containing the MasterExam software. This software gives two ways to do its questions, like the real exam or "ad-hoc". The MasterExam's questions are like the book. A "permission" to get a bonus exam also come with the CD, you just need to register on their site and then download the program.
- Other resources for exercises that I found:
- Whizlabs: There is a software like MasterExam made by Whizlabs. It seems to be a very good software. Its interface is great and you have the possibility to do "adaptive" tests. I downloaded a trial version from their website and I liked it pretty much.
- EPractize: Their software is like the MasterExam too but it doesn't have any strength point. I didn't like the software's interface. I also downloaded a trial version from their website.
- "TestKiller": This one is an exercise's book and seems to be made by Troytec. It's a very weird book, with a lot of writing mistakes on it. The strength point is that it promises to cover only questions from the real exam. When I took the exam I had the feeling of recognizing one or two questions (I took a look on 60 from 224 questions of this book).
My study schedule: That was the way I worked out to pass the exam. - 8 months to read the SCJP Sun Certified Programmer for Java 5 Study Guide (Exam 310-055) and to do all exercises. It took me something like one hour per day (only workdays). It's a good way to start because you can understand how Java works without pushing yourself.
- 1 month to read again all "Two-minute Drill" sections and the most complicated chapters (chapters 7, 9, 8, 6, in descending difficulty order, in my opinion).
- 4 days (eight hours per day) to do A LOT of exercises. This is the main point. The exercises are full of tricks and the only way to become familiar with those tricks is doing a lot of exercises.
The exam: In my opinion, the exam is difficult. You have to be really confident before taking it. A good thing that I noticed was that the time is enough to do everything with attention and patience. In my opinion to take this exam you must know about everything, but with a special care with these points below: - Threads.
- Generics.
- Methods Override/Overload (and covariant return).
- Box/Unbox.
- Method calling with widening and autoboxing.
- Access Control.
- java and javac commands.
- Differences between collections (Ordered, Sorted, Hash).
- How equals and hashCode works with collections.
- Inner Classes.
Differences between SCJP 310-055 and 310-065 (you can find it here): - Questions concerning System.gc() have been removed.
- Coverage of the java.io.Console class has been added.
- Coverage of navigable collections has been added.
- Several of the previous objectives have been strengthened (so you can expect more questions and more detailed questions on them). These strengthened objectives include: exception handling, collection classes and collection interfaces, assertions, threads, and flow control.
- Number of questions: 310-055 = 72; 310-065 = 72
- Pass score: 310-055 = 59%; 310-065 = 65%
- Time limit: 310-055 = 175 minutes; 310-065 = 210 minutes
Advice: If you aren't feeling confident to take the SCJP 6 exam just because you don't know what is new in this version, don't take the SCJP 5. I did it and I am a little regretful. There is no "SCJP 5 to 6" exam, there is only one "upgrade" exam to version 6 called "Exam 310-056". In this exam you have to prove your Java 5 knowledge again. Well, soon I will take the 310-056 and then I will post about it. Please comment and share your experiences with SCJP (any version is welcome :)). Links:
Sometime ago I was surprised with a peculiar "tip of the day" which simply mentioned a traditional angel cake recipe.
Well, today I got the confirmation. There's certainly a cook amongst JDev's developers!
Look at the "tip" showed to me today:

Hmmmm... interesting... :)
by Eduardo Rodrigues Attention!!!Today, my Windows XP automatically upgraded to SP3 and, after rebooting, my JDev 10.1.3.3 began to crash during its initialization, generating a JVM core dump in directory <JDEV_HOME>\jdev\bin. After a quick look into the dump file, I noticed some problem with VFS, so I decided to disable VFS commenting the following line in file <JDEV_HOME>\jdev\bin\jdev.conf: #AddVMOption -DVFS_ENABLE=trueThen, thank God, JDev came back to life again. So, don't panic. Cheers!
by Fábio Souza Before I start, I would like to say that many texts and observations were took from the Oracle® Containers for J2EE Services Guide 10g (10.1.3.1.0), Chapter 7. What is it?The Java Object Cache (JOC) is a OC4J service that makes cache (in memory or disk) of any kind of Java object. Use it: - To store frequently used objects.
- To store objects that are costly to create/retrieve.
- To share objects between applications.
Characteristics: - By default, cached objects are stored in memory but disk persistence can be configured.
- By default, cached objects are local. The DISTRIBUTE mode can be configured.
- By default, the "write lock" is disabled.
- Cached objects doesn't have a "read lock".
- Cached objects are represented by name spaces.
- Cached objects are invalidated based on time or an explicit request.
- Cached objects can be invalidated by group or individually.
- Each cached Java object has a set of associated attributes that control how the object is loaded into the cache, where the object is stored, and how the object is invalidated.
- When an object is invalidated or updated, the invalid version of the object remains in the cache as long as there are references to that particular version of the object.
The Java Object Cache organization: - Cache Environment. The cache environment includes cache regions, subregions, groups, and attributes. Cache regions, subregions, and groups associate objects and collections of objects. Attributes are associated with cache regions, subregions, groups, and individual objects. Attributes affect how the Java Object Cache manages objects.
- Cache Object Types. The cache object types include memory objects, disk objects, pooled objects, and StreamAccess objects.
This table gives a little description about the cache environment and the object types.
JOC API:Only "cache.jar" must be added to application's classpath to start with JOC API. This archive is located in $ORACLE_HOME\javacache\lib\cache.jar. A project in JDeveloper just needs to import the built-in "Java Cache" library. Distributed Cache Characteristics: - The cache management is not centralized. Cache updates and invalidation are propagated to all application server nodes.
- The OAS' JOC configuration of each OAS node is not propagated to other nodes.
- The distributed objects must be in the same namespace in each node.
Distributed Cache Configurations:
There are two ways to configure JOC: programmatically (using the oracle.ias.cache.Cache class) and through the javacache.xml file. This post only covers javacache.xml.
Configuring the javacache.xml file:
The javacache.xml localization is specified in the server.xml OC4J configuration file (tag: "<javacache-config>"). To work with javacache.xml it is necessary to start the container with the -Doracle.ias.jcache=true property.
To run JOC in "distributed mode", <communication> tag must be configured in the javacache.xml file like the example below:
<communication>
<!-- "isdistributed" must be "true" to JOC work with DISTRIBUTE marked objects -->
<isdistributed>true</isdistributed>
<!-- Each JOC node must have a "discoverer" element to itself. -->
<discoverer ip="192.168.0.2" port="7000">
<discoverer ip="192.168.0.3" port="7000">
</communication> Configuring the distributed cached objects:There are three important attributes that we can use when configuring objects: - DISTRIBUTE: used to mark objects that will be shared between applications.
- SYNCHRONIZE: used to allow "write locking" on cached objects.
- SYNCHRONIZE_DEFAULT: the same use as the SYNCHRONIZE attribute, but it can mark only a region or a group. When they are marked, all objects will be allowed to use the write lock.
The example below shows a distributed cache utilization:
public void defineRegions() {
// Creating attributes
Attributes remoteRegionAttr = new Attributes();
/*
* Extracted from Attributes.setFlags() javadoc:
* specifies which of the listed attributes should be set in the Attributes object.
* The flags may be OR'ed together, i.e., Attributes.DISTRIBUTE | Attributes.SPOOL.
* Any previous settings will be disregard.
*/
remoteRegionAttr.setFlags(Attributes.SYNCHRONIZE_DEFAULT | Attributes.DISTRIBUTE);
try {
// Creates the "RemoteRegion" with the specified attributes.
CacheAccess.defineRegion("RemoteRegion", remoteRegionAttr);
} catch (Exception e) {
e.printStackTrace();
}
}
public void createCachedObject(Object object) {
CacheAccess access = null;
try {
// Accessing the created region.
access = CacheAccess.getAccess("RemoteRegion");
// Owning cache object's write lock (5 seconds to timeout)
access.getOwnership("CachedObject", 5000);
// Caching the object
access.put("CachedObject", object);
// Releasing cache object's write lock (5 seconds to timeout)
access.releaseOwnership("CachedObject", 5000);
} catch (Exception ex) {
ex.printStackTrace();
} finally {
if (access != null) {
/*
* Extracted from CacheAccess.close() javadoc:
* releases the resource used by current CacheAccess object.
* Application is required to make this call when it no longer need this CacheAccess instance.
*/
access.close();
}
}
}
public Object retrieveCachedObject() {
Object object = null;
CacheAccess access = null;
try {
access = CacheAccess.getAccess("RemoteRegion"); // Accessing the created region.
/*
* Extracted from CacheAccess.get() javadoc:
* returns a reference to the object associated with name.
* If the object is not currently in the cache and a loader object has been
* registered to the name of the object, then the object will be loaded into
* the cache. If a loader object has not been defined for this name, then, for
* DISTRIBUTE object, the default load method will do a netSearch for the object
* to see if the object exist in any other cache in the system; for a non
* DISTRIBUTE object, an ObjectNotFoundException will be thrown. The object
* returned by get is always a reference to a shared object. Get will always
* return the latest version of the object. A CacheAccess object will only
* maintain a reference to one cached object at any given time. If get is called
* multiple times, the object accessed previously will be released.
*/
object = access.get("CachedObject");
// It's not necessary to own the writing lock to read cached objects.
} catch (Exception ex) {
ex.printStackTrace();
} finally {
if (access != null) {
/*
* Extracted from CacheAccess.close() javadoc:
* releases the resource used by current CacheAccess object.
* Application is required to make this call when it no longer need this CacheAccess instance.
*/
access.close();
}
}
return object;
}
Concurrent access sensible applications may need read and write synchronism. Because JOC only offers write lock, I had to "force" read lock. This is the solution I found:
/**
* This method reads and updates a cached object forcing synchronizing both to
* reading and writing.
* If it is being executed in multiple threads, each thread will only be able to
* read the object when another thread release it's writing lock. The writing lock will
* be released after a thread finishes it's reading and writing.
*/
public void synchronizedReadUpdateCachedObject() {
CacheAccess access = null;
try {
access = CacheAccess.getAccess("RemoteRegion");
access.getOwnership("CachedObject", 5000);
Object object = access.get("CachedObject");
System.out.println(object.toString());
Object newCachedObject = "New Cached Object";
// This is the method used to update cached objects.
access.replace("CachedObject", newCachedObject);
access.releaseOwnership("CachedObject", 5000);
} catch (Exception ex) {
ex.printStackTrace();
} finally {
if (access != null) {
access.close();
}
}
} Declarative Cache:The JOC offers a way to configure its regions, subregions, groups and objects using XMLs. To use this feature the "preload-file" tag must be added to the javacache.xml. This tag will point to the XML with the environment definitions. More information at: http://http//download.oracle.com/docs/cd/B32110_01/web.1013/b28958/joc.htm#i1085809 CacheWatchUtil:By default, the Cache Service provides the CacheWatchUtil cache monitoring utility that can display current caches in the system, display a list of cached objects, display caches' attributes, reset cache logger severity, dump cache contents to the log, and so on. It depends on the "dms"library. To execute:
java -classpath $ORACLE_HOME\lib\dms.jar;$ORACLE_HOME\javacache\lib\cache.jar oracle.ias.cache.CacheWatchUtil -config=<path_to_javacache.xml> More Oracle Application Server 10g caches (entirely took from OC4J documentation): - Oracle Application Server Web Cache. The Web Cache sits in front of the application servers (Web servers), caching their content and providing that content to Web browsers that request it. When browsers access the Web site, they send HTTP requests to the Web Cache. The Web Cache, in turn, acts as a virtual server to the application servers. If the requested content has changed, the Web Cache retrieves the new content from the application servers.
The Web Cache is an HTTP-level cache, maintained outside the application, providing fast cache operations. It is a pure, content-based cache, capable of caching static data (such as HTML, GIF, or JPEG files) or dynamic data (such as servlet or JSP results). Given that it exists as a flat content-based cache outside the application, it cannot cache objects (such as Java objects or XML DOM—Document Object Model—objects) in a structured format. In addition, it offers relatively limited postprocessing abilities on cached data.
- Web Object Cache. The Web Object Cache is a Web-application-level caching facility. It is an application-level cache, embedded and maintained within a Java Web application. The Web Object Cache is a hybrid cache, both Web-based and object-based. Using the Web Object Cache, applications can cache programmatically, using application programming interface (API) calls (for servlets) or custom tag libraries (for JSPs). The Web Object Cache is generally used as a complement to the Web cache. By default, the Web Object Cache uses the Java Object Cache as its repository.
A custom tag library or API enables you to define page fragment boundaries and to capture, store, reuse, process, and manage the intermediate and partial execution results of JSP pages and servlets as cached objects. Each block can produce its own resulting cache object. The cached objects can be HTML or XML text fragments, XML DOM objects, or Java serializable objects. These objects can be cached conveniently in association with HTTP semantics. Alternatively, they can be reused outside HTTP, such as in outputting cached XML objects through Simple Mail Transfer Protocol (SMTP), Java Message Service (JMS), Advanced Queueing (AQ), or Simple Object Access Protocol (SOAP).
References:Oracle Application Server Containers for J2EE Services Guide 10g Release 3 (10.1.3)
Oracle Application Server 10g (10.1.2) JOC Tutorial
Oracle Application Server 10g (10.1.2) JOC javadoc
by Eduardo Rodrigues One of the many companies recently acquired by Oracle is a small one called " Auptyma", whose founder and former CEO, Mr. Virag Saksena, was previously Director of the CRM Performance Group at Oracle. It's main contribution for Oracle's fast growing product line was its "Java Application Monitor" which is now part of the "Oracle Fusion Middleware Management Packs" (that's where http://www.auptyma.com now takes us to) and was renamed to "Oracle Application Diagnostics for Java" or simply Oracle AD4J (although it's also referred as JADE as in Java Application Diagnostics Expert). Holy alphabet soup! The "new" component integrates the Oracle Enterprise Manager 10g Grid Control suite but it also lives as a separate product, which is great, specially for us developers. It can be downloaded from http://www.oracle.com/technology/software/products/oem/htdocs/jade.html. The installer is very small and also very easy and intuitive. AD4J may seem awkward at first, when you notice the fact that it also installs and uses the old Apache JServ and a PostgreSQL database. But it's worth it! I've tried AD4J with my OC4J 10.1.3.3 standalone and I can say it works pretty well and is certainly a much more interesting and useful diagnostics tool than OracleAS 10g Control Console with JVM metrics enabled. My only extra work was to reinstall JDK 1.5.0_14 and reconfigure OC4J to use it (I was already update 15) because it's the most recent JDK 1.5.0 update currently supported by AD4J. Its main features includes: - Production diagnostics with no application instrumentation, saving time in reproducing problems.
- Visibility into Java activity including in-flight transactions, allowing administrators to proactively identify issues rather than diagnosing after-the-fact (application hangs, crashes, memory leaks, locks).
- Tracing of transactions from Java to Database and vice-versa, enabling faster resolution of problems that span different tiers.
- Differential heap analysis in production applications.
- Possibility to setup alerts based on configured thresholds and forward them using SNMP (which means potential integration with other enterprise monitoring products like OpenView, for instance)
As you can see, it's a pretty interesting, yet small and simple, diagnostic and monitoring tool for Java applications. You can also check these resources for further info: Cheers and... keep reading!
by Eduardo Rodrigues IntroductionI think I've already mentioned it here but, anyway, I'm currently leading a very interesting and challenging project for a big telecom company here in Brazil. This project is basically a complete reconstruction of the current data loading system used to process, validate and load all cellphone statements, which are stored as XML files, into an Oracle CMSDK 9.0.4.2.2 repository. For those who aren't familiar, Oracle CMSDK is an old content management product, which has succeeded the older Oracle iFS (Internet File System). Because it's not an open repository, we are obligated to use its Java API if we want to programmatically load or retrieve data into or from the repository. That, obviously, prevents us from taking advantage of some of the newest tools available like Oracle's XML DB or even the recent Oracle Data Integrator. MotivationOne of our biggest concerns in this project is with the performance the new system must deliver. The SLA is really aggressive. So, we decided to make some research to find out the newest XML processing technologies available, try and compare them in order to make sure which ones would really help us in the most efficient way. The only constraints are: we must not consider any non-industry-standard solution nor any non-production (or non-stable) releases. Test SceneriesThat said, based on research and also on previous experience, these were the technologies I've chosen to test and compare: I've initially discarded DOM parsers based on the large average size of the XML files we'll be dealing with. We most certainly can't afford the excessive memory consumption involved. I've also discarded Oracle StAX Pull Parser, because it was still a preview release, and J2SE 5.0 built-in XML parsers, since I know they're a proprietary implementation of Apache Xerces based on a version certainly older than 2.9.1. The test scenery designed was very simple and was intended only to measure and compare performance and memory consumption. The test job would be just to parse a real-world XML file containing 1 phone statement, retrieving and counting a predefined set of elements and attributes. In summary, rules were (for privacy's sake, real XML structure won't be revealed): - Parse all occurrences of "/root/child1/StatementPage" element
- For each <StatementPage> do:
- Store and print out value of attribute "/root/child1/StatementPage/PageInfo/@pageNumber"
- Store and print out value of attribute "/root/child1/StatementPage/PageInfo/@customerCode"
- Store any occurrence of element <ValueRecord>, along with all its attributes, within page's subtree
- Print out the number of <ValueRecord> elements stored
- Print out the total number of <StatementPage> elements parsed
- Print out the total number of <ValueRecord> elements parsed
Also, every test should be performed for 2 different XML files: a small file (6.5MB), containing a total of 420 statement pages and 19,133 value records and a large one (143MB) with 7,104 pages and 464,357 value records. Based on the rules above, I then tested and compared the following technology sets: - Apache Digester using Apache Xerces2 SAX2 parser
- Apache Digester using Oracle SAX2 parser
- Sun JAXB2 using Xerces2 SAX2 parser
- Sun JAXB2 using Oracle SAX2 parser
- Sun JAXB2 using Woodstox StAX1 parser
- Pure Xerces2 SAX2 parser
- Pure Oracle SAX2 parser
- Pure Woodstox StAX1 parser
Based on this tutorial fragment from Sun: http://java.sun.com/webservices/docs/1.6/tutorial/doc/SJSXP3.html and considering that performance is our primary goal, I've chosen StAX's cursor API (XMLStreamReader) over iterator. Still aiming for performance, all tested parsers have been configured as non-validating. In time; all tests were executed on a Dell Latitude D620 notebook, with an Intel Centrino DUO T2400 CPU @ 1.83GHz running on Windows XP Professional SP2 and Sun's Java VM 1.5.0_15 in client mode. ResultsThese were the performance results obtained after parsing the small XML file (for obvious reasons, I decided to measure heap usage only when the large file was parsed): 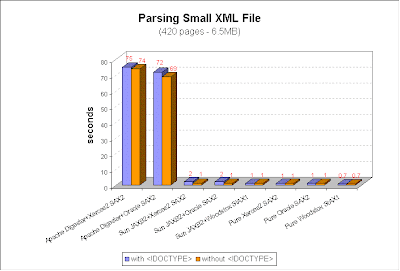 As you can see, Apache Digester's performance was extremely and surprisingly poor despite all my efforts to improve it. So, I had no other choice than to discard it for next tests with the large XML file, from which the results are presented bellow:  Notice that the tendency toward a better performance when <!DOCTYPE> tag is removed from the XML document has been clearly confirmed here. As for memory allocation comparison, I've once again narrowed the tests only to the worst case from performance tests above: large XML file including <!DOCTYPE> tag. The results obtained from JDev's memory profiler were:  Another interesting information we can extract from these tests is how much XML binding represents in terms of overhead when compared to a straight parser:  ConclusionAfter a careful and thorough revision and confirmation of all results obtained from the tests described here, I tend to recommend a mixed solution. Considering its near 12MB/s throughput verified here, I'd certainly choose pure Woodstox StAX parser every time I'll have to deal with medium to large XML sources but, for convenience, I'd also choose JAXB 2 whenever there's a XML schema available to compile its classes from and the size of the source XML is not a concern. As for complexity, I really can't say that any one of the tested technologies was found considerably more complex to implement than the others. In fact, I don't think this would be an issue for anybody with an average experience with XML processing. Important NoteJust for curiosity, I've also tested Codehaus StaxMate 1.1 along with Woodstox StAX parser. It's a helper library built on top of StAX in order to create an easier to use abstraction layer for StAX cursor API. I can confirm the implementor's affirmation that StaxMate shouldn't represent any significant overhead for performance. In fact, performance results were identical when compared to pure Woodstox StAX parsing the large XML file. I can also say that it really made my job pretty easier. The only reason I won't consider StaxMate is that it depends on a StAX 1.0 API non-standard extension which is being called "StAX2" by guys at Codehaus. That's all for now. Enjoy and... keep reading!
Great news folks!
We've just fixed our blog's template so it'll be displayed 100% correctly on Internet Explorer 6 browser. Now, we expect this blog to render identically on both Internet Explorer and Firefox (hopefully on all other browsers too).
Please, let us know if there's still any visualization issues.
Cheers and... keep reading!
This week I found something at least very curious when I launched my JDeveloper 10.1.3.3 as I do almost every morning. This was the "Tip of the Day" it showed me:

Well, I don't know what this means but, anyway, here is a full recipe, just in case: http://www.foodnetwork.com/food/recipes/recipe/0,1977,FOOD_9936_15602,00.html
:)
by Fábio Souza  These days I've been looking for a good way to incorporate FindBugsTM within my JDeveloper 10g and I couldn't find anything about it on the net. I talked with Eduardo and we both thought it would be a good idea to configure FindBugs as a JDeveloper External Tool (and it is indeed). Ok, before I start listing the steps to do it, I must say I'm pretty much aware of the fact that you will probably notice that I'm using Eduardo's JAXB 2.0 configuration steps listed on his previous post " JAXB 1.0 vs. 2.0 in JDeveloper 10g". Well... what can I say? I am a CTRL+C/CTRL+V addicted and I just can't help it! :D - Click the menu item "Tools -> External Tools..."
- Press the "New..." button to start the "Create External Tool" wizard
- Select "External Program" as the "Tool Type" and press "Next"
- Fill the 3 displayed fields as follows:
- Program Executable:
full path to the "java.exe" from your preferred JAVA_HOME (must be Java 5.0 or greater)
- Arguments:
-Dfindbugs.home=. -Xmx256m -jar lib\findbugs.jar -sourcepath "${project.first.sourcepath}" -auxclasspath "${project.classpath}" -html -output "${project.dir}\${file.name.no.ext}.findbugs.html" "${project.outputdirectory}" "${project.outputdirectory}"
The arguments above will be passed to "java.exe". Notice that we're bypassing "findbugs.bat" and executing the FindBugs JAR file directly. We must do this way because the batch file requires the classpath passed after "-auxclasspath" to be enclosed in double quotes (") and the macro "${project.classpath}" will match that requirement only when there's at least one path including one ore more blank spaces in its directories names.
- Run Directory:
full path where FindBugs is installed.
- Press "Next" to advance to "Display" step and fill the 3 fields as you like. I suggest the following:
- Caption for Menu Items:
FindBugs
- ToolTip Text:
Run FindBugs on your project.
- Icon location:
Download and configure this one -> 
- Press "Next" to advance to "Integration" step where I recommend selecting "Tools Menu" and "Navigator Context Menu"
- Press "Next" to advance to the final step "Availability". Here, you have to choose the option "When Specific File Types are Selected" and then move only the item "Java Project" from list "Available Types" to list "Selected Types"
- Press "Finish" and done!
Attention! I got an error while trying to use FindBugs in my JDeveloper 10.1.3.3. When " ${project.classpath}" is expanded after " -auxclasspath", it includes the Java library paths as well. But, I don't know why, the default JDeveloper's Java SE library has i18n.jar, sunrasign.jar and the " classes" folder included in its classpath but these three items actually don't exist, so FindBugs will abort when it tries to locate them. I had to remove these items from my JDeveloper Java SE Library classpath to solve this problem. Now it's all set to use FindBugs! Just right-click on a project in the Application Navigator and select " FindBugs". An HTML report will be generated in project's folder and standard output and error will be sent to JDev's Message View. Enjoy your new tool!
by Eduardo Rodrigues Hi everybody! Recently we've upgraded OracleAS environments in one of our biggest clients here in Brazil from version 10.1.3.0.0 to version 10.1.3.3.0. To do that, we've applied patchset # 6148874 (which can be downloaded from Oracle Metalink) carefully following all the instructions found in its installation guide. As expected, the patchset application went perfectly fine and all of our configured containers and applications were still there, up and running, and everybody was happy... until we noticed that one of our oldest and most annoying problems was still there: using ASControl to manage our clustered production environment sometimes was just impossible due to its unacceptable performance when trying to access anything in cluster topology context. Unfortunately, the only workaround we knew was to restart ASControl application in the cluster's "master node" (the node elected to run the ascontrol application). Fortunately, today I found the problem and also the solution for this situation. There's a documented bug on Metalink (bug # 6601697) explaining that this problem is caused by the underlying RMI communication between the ASControl 10.1.3.3.0 and the other components of the cluster. ASControl uses RMI protocol to connect to other nodes, makes some request and then waits for a response. The problem is that there's no timeout for this response waiting. If one or more components are in a heavy load situation, for example, ASControl will keep waiting for their responses, which can take too long, causing the impression that ASControl stopped working. In fact, this problem is known since version 10.1.3.1.0 but it seems that patchset 10.1.3.3.0 does not include the correction as it should. So, for now, the solution is to apply the one-off patch # 6124143, also found on Metalink. This patch is originally targeted to OracleAS 10.1.3.1.0 but, as written in bug #6601697, it's ok to apply it on version 10.1.3.3.0 though. We just have to follow these simple instructions, found in the bug, before actually applying it: - Edit the patch file etc/config/actions and replace 10.1.3.1.0 by 10.1.3.3.0
- Edit etc/config/inventory and replace 10.1.3.1.0 by 10.1.3.3.0
Once it's successfully applied, we must use ASControl to navigate to the OC4J instance where ascontrol application is running (typically the "home" instance). Click on Administration -> Server Properties -> Command Line Options -> Start-parameters: Java Options and add "-Drmi.client.connection.timeout= X", where " X" should be the number of seconds to wait for a RMI response before timeout. The bug suggests 5 seconds. We've successfully applied this one-off patch in our OracleAS 10.1.3.3.0 environment and, until now, it seems to have solved the problem. I feel this might be a problem faced by many other OracleAS 10.1.3 users so I hope this post can help them. Cheers and... keep reading!
This one is for all Sun Certified Java Programmers out there.
You’re all invited to join the SCJP Group on LinkedIn. Joining will allow you to find and contact other certified members on LinkedIn. The goal of this group is to help members:
- Reach other certified programmers
- Accelerate careers/business through referrals from group members
- Know more than a name – view rich professional profiles from fellow SCJP Group members
 Click here to join now! Click here to join now!Hope to see you in the group soon. Cheers and keep reading...
by Fábio Souza Hello everybody! This is my debut post to Java 2 Go! (ironically it's not about Java) and I'm really happy for having been invited to write by Eduardo. I hope you will enjoy as much as I am! As the title says, this is a short how-to about the use of regular expressions in Oracle Database. This feature was introduced in Oracle 10g and is really helpful, useful and, better off, not too complicated. Let's take a look. There are three built-in SQL functions and one operator for working with regular expressions in Oracle 10g: - OPERATOR:
- REGEXP_LIKE
It's used in the WHERE clause with column filtering purpose. The filter is the informed pattern.
- FUNCTIONS:
- REGEXP_INSTR
Returns the initial position where the informed pattern was found.
- REGEXP_SUBSTR
Returns the result of the informed pattern application.
- REGEXP_REPLACE
Replaces the informed pattern with another given string.
NOTE: pattern is the regular expression which is used to match specific regions of a string. This example will show only the REGEXP_REPLACE function and the intention is to return only the value of field "Login". -- Description:
-- First argument: string which the pattern will be applied to (it's possible to use a column instead).
-- Second argument: the pattern.
-- Third argument: new string that will replace the portion of the original string matching the given pattern.
select REGEXP_REPLACE(
'ID = 13737009 - Login = T123456 - Status nonAdmin - WorkingPlace = HeadQuarter - Sector = B',
'(.+)(Login = )([^ ]+)(.+)',
'\3')
from dual;The pattern used above defines four groups between parenthesis: - "(.+)" matches 1 or more characters
- "(Login = )" matches the exact substring "Login = "
- "([^ ]+)" matches 1 or more character different from " " (space)
- "(.+)" again, matches 1 or more characters
In our example, the result for each group above is: - "ID = 13737009 - "
- "Login = "
- "T123456"
- " - Status nonAdmin - WorkingPlace = HeadQuarter - Sector = B"
For the simple query above, the result of function "REGEXP_REPLACE" will be the replacement of the substring matching the given pattern with "\3". The presence of character "\" tells the function to replace "\3" with the substring matching the third group defined in the given pattern, which is "([^ ]+)". As you may notice, in this case, the given pattern matches the entire string so, at the end, the entire string will be replaced with "T123456". Despite the beauty of this, there's one thing we should always keep in mind: performance. As we already know, applying functions to table columns in WHERE clauses typically makes Oracle's choice optimizer to ignore any index on that particular column which may result in a table full scan. If we're dealing with big volumes, this might be a huge concern. Thank God Oracle gives us some options like Partitioning and Parallel Queries. That's all for now. If you'd like to get further information on the subject I recommend reading this article from OTN: http://www.oracle.com/technology/oramag/webcolumns/2003/techarticles/rischert_regexp_pt1.htmlCheers! (and keep reading...)
Hi folks!
It's with the greatest satisfaction that I welcome the blog's most recent "acquisition": the Oracle consultant Fábio Saraiva de Souza. You may check his profile here.
Fábio is a good friend with whom I've had the opportunity to work for almost a whole year in my last project. As you will certainly notice, Fábio is one of that curious guys that are never satisfied until they really understand things to their deepest details.
Welcome Fábio! We'll be willing to read from you soon.
by Eduardo Rodrigues Hi everybody! You must have noticed that JDeveloper may be boosted by a great number of extensions provided either by Oracle itself or by an open source and partners community. If you did not noticed that yet, then you certainly should do so. Even if it's just for curiosity, you may check a complete list of all extensions available selecting the menu item "Help -> Check for Updates...". It's important to say that for this feature to work properly, your JDev's web proxy configuration must be correct. So it's worth to take a look at this first by selecting menu item "Tools -> Preferences...":  Now that we're all set, let's go back to the "Help -> Check for Updates..." thing. On the wizard's first step you should make the following selection:  After pressing "Next" you'll be presented to a list of available extensions from the update centers selected before. Browse the list and see how many interesting and useful stuff you can add to your JDeveloper environment. All you have to do is to select the extensions you like and proceed with the wizard. After restarting JDeveloper will automatically install all downloaded extensions. I recommend that you always restart JDeveloper immediately when prompted to. An alternative way to browse and download these extensions outside JDeveloper is to visit the following URLs: In this case, to install them, use the feature "Install From Local File" in "Help -> Check for Updates..." wizard:  As a suggestion, here is a list of my favorite extensions: - MUST HAVE
- Oracle ADF SRDemo Applications
Great way to learn ADF by example. Comes in 2 flavors: EJB 3.0 + Toplink Essentials JPA or ADF BC
- Oracle ADF Developer's Guides Update
- JDeveloper Spring 2.5 Support
Adds support for creating and editing Spring 2.5 bean defintions. This addin will create the Spring 2.5 library and register the relevant XSDs and DTDs with the IDE to provide a productive editing experience for Spring definitions
- Struts Documentation 10.1.3
Complete Javadoc for Struts
- Variable Highlighter Extension
Dynamically highlights variables as you click on them
- Subversion VCS Extension
Much better version controller than plain CVS
- USEFUL
- JUnit Integration Extensions
Various extensions providing integrated support for JUnit
- Oracle JHeadstart Evaluation Version
Oracle JHeadstart is a productivity toolkit that works on top of Oracle ADF. Using ADF Faces as View, JSF as Controller and ADF Business Components as Business Service, JHeadstart generates sophisticated ADF web applications using simple metadata. Generated features include wizards, shuttles, trees, list of values, multi-row insert/update/delete, advanced and quick search capabilities, file upload/download, deeplinking, conditionally dependent items, dynamic breadcrumbs and more.
- Copy As HTML
Great extension that makes the task of copying bits of source code to blogs much easier
- XPath Search Extension
Best way to search inside XML documents
- Make Read-only Files Writable
- GWT Developer
Provides visual editing environment to help with developing with the Google Web Toolkit (GWT)
- PMD JDeveloper Extension
Provides integrated support for PMD 4.1
- Remove Workspaces and Projects
Adds a context menu option that allows the deletion of projects and workspaces and of their sub-contents, quick and easy.
- Additional Skins for ADF Faces
- Zipper
This extension provides a simple ZIP feature for applications and projects
On the other hand, the extension "JDeveloper Keep Resident (for Windows only)" is definitely one that you should NOT use. That's an experimental extension, works only on Windows and the very same effect may be achieved in a much better way which has already been explained in a previous post. Finally, if you want to contribute with your own great JDeveloper extension, you may install "JDeveloper Extensions SDK" which is an extension itself and includes documentation and sample extensions. That's all for now. Cheers and... keep reading!
I got tagged in the Oracle Blogsphere tag game by Juan Camilo Ruiz so now it's my turn. 8 things you didn't know about me:
- I got married for the 2nd time on Sep. 7th, 2007 with the most beautiful and amazing woman I've ever met in my entire life and her name is Heloisa. I hope this one is forever.
- My first computer ever was a TK-85 based on Sinclair architecture with a Z80 CPU and 16KB of RAM. I was 12 years-old and my first Basic program was:
10 PRINT "Eduardo ";
20 GOTO 10;
Cooooool!!! =)
- I totally hate traffic jams! That's why I could never live in São Paulo, Brazil. I would certainly die from a heart attack really soon.
- If I could choose a place to live here in Brazil, I'd choose Florianópolis (The Island of Magic). And not only because my wife was born there.
- When I was a child, I suffered a lot from bronchitis. Doctors recommended swimming as a long term treatment so my parents forced me to attend swimming classes, which I used to hate. Now I'm 100% cured and love to swim. Kids...
- My father is a presbyterian minister just like my grandfather was too. My grandfather, Rev. Zaqueu Ribeiro, founded a presbyterian church in Rio de Janeiro, in a neighborhood called "Tijuca".
- For almost a half of my life, I spent practically every holiday at my family's country house in a very small city called Eng. Paulo de Frontin near Rio de Janeiro. Unfortunately, after my grandfather's death, my family ended up selling the house. Too bad.
- I've always wanted to ride a jet ski but never got the chance to do it :(
Well, let me see who I'm going to tag next... Steve Button, Carlos Rubinstein, Debu Panda, Mike Lehmann, Frank Nimphius, Olaf Heimburger, Steve Muench and Marcos Campos. Come on guys! Let's play!
by Eduardo Rodrigues Ok, I know JDeveloper 10g already comes with an embedded JAXB compiler which can be found in menu "Tools -> JAXB Compilation...". The only problem with this compiler is that it's a JAXB 1.0 implementation and, believe me, the differences are simply HUGE when compared to it's successor, JAXB 2.0. And all for the very best. To prove my point, let's go through a simple example comparing both JAXB versions. First of all, let's create a new application in JDeveloper with one empty project called "JAXB 1.0" adding only "XML" to its technology scope:  We must have a valid DTD or XML Schema so the JAXB compiler can work. Let's consider this small and simple XML Schema borrowed from a W3C tutorial:
<?xml version="1.0" encoding="ISO-8859-1" ?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<!-- definition of simple elements -->
<xs:element name="orderperson" type="xs:string"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="address" type="xs:string"/>
<xs:element name="city" type="xs:string"/>
<xs:element name="country" type="xs:string"/>
<xs:element name="title" type="xs:string"/>
<xs:element name="note" type="xs:string"/>
<xs:element name="quantity" type="xs:positiveInteger"/>
<xs:element name="price" type="xs:decimal"/>
<!-- definition of attributes -->
<xs:attribute name="orderid" type="xs:string"/>
<!-- definition of complex elements -->
<xs:element name="shipto">
<xs:complexType>
<xs:sequence>
<xs:element ref="name"/>
<xs:element ref="address"/>
<xs:element ref="city"/>
<xs:element ref="country"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="item">
<xs:complexType>
<xs:sequence>
<xs:element ref="title"/>
<xs:element ref="note" minOccurs="0"/>
<xs:element ref="quantity"/>
<xs:element ref="price"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="shiporder">
<xs:complexType>
<xs:sequence>
<xs:element ref="orderperson"/>
<xs:element ref="shipto"/>
<xs:element ref="item" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute ref="orderid" use="required"/>
</xs:complexType>
</xs:element>
</xs:schema>Just copy the code above to a file named "shiporder.xsd" in the project's root directory so it will automatically show in project's "Resources" folder:  Now select file "shiporder.xsd" in the application navigator, click the menu item "Tools -> JAXB Compilation..." and fill up the pop-up shown as the screenshot bellow:  After pressing the "OK" button, you should see the following scenario:  As you can see, the JAXB compiler generates a bunch of classes and interfaces reflecting the structure defined by the compiled XML Schema. If you look closer, you'll notice that some of the classes extend "oracle.xml.jaxb.JaxbNode" (like class ShiporderTypeImpl, for instance). That's because the built-in JAXB compilation feature we just showed relies on a JAXB 1.0 proprietary implementation provided by Oracle in its XML Developer Kit which comes with JDeveloper. You may get more details on this at Oracle XDK Home site. Continuing with our test case, let's create a sample "testorder.xml" based on our shiporder.xsd schema:
<?xml version="1.0" encoding="ISO-8859-1" ?>
<shiporder orderid="0001" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="shiporder.xsd">
<orderperson>Eduardo Rodrigues</orderperson>
<shipto>
<name>John Doe</name>
<address>#100, Oracle Parkway</address>
<city>Redwood City</city>
<country>USA</country>
</shipto>
<item>
<title>DVD+RW</title>
<quantity>50</quantity>
<price>.50</price>
</item>
<item>
<title>17" LCD Monitor</title>
<quantity>5</quantity>
<price>150.00</price>
</item>
<item>
<title>Bluetooth Mouse</title>
<quantity>10</quantity>
<price>40.00</price>
</item>
</shiporder>To read in and process this sample XML using the package generated by Oracle's JAXB compiler, we must use the JAXB feature called "Unmarshal". To do that, I'll modify class test.jaxb1.TestJAXB1 like this:
package test.jaxb1;
import java.io.File;
import java.util.List;
import javax.xml.bind.JAXBContext;
import javax.xml.bind.JAXBException;
import javax.xml.bind.Marshaller;
import javax.xml.bind.Unmarshaller;
import test.jaxb1.shiporder.*;
public class TestJAXB1 {
static JAXBContext context = null;
public static void main(String[] args) {
try {
context = JAXBContext.newInstance("test.jaxb1.shiporder");
Unmarshaller unmarshaller = context.createUnmarshaller();
Shiporder order = (Shiporder)unmarshaller.unmarshal(new File("testorder.xml"));
System.out.println("Items included in order #"+order.getOrderid()+" are:");
for (ItemTypeImpl item : (List<ItemTypeImpl>)order.getItem()) {
System.out.println("\t:. "+item.getTitle()+" - "+
item.getQuantity()+" item(s) at $"+item.getPrice()+" each");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}Making a long story short, the "magic" performed by the Unmarshaller is basically to parse the XML using the classes generated by the JAXB compiler to map its entire content into memory. It's just like using a DOM parser to load the XML's DOM tree into memory. The advantage here is that the names, attributes and methods in JAXB generated objects strictly reflect the XML's structure defined by its schema making it much easier and more intuitive to work with them instead of a pure DOM tree. Running the test above, the outcome should be:  Quite easy. You'd probably think: Well... I'm ok with that. It's easy enough already. The question is: is that so??? NOT!!!Now I will repeat the same test case described above only upgrading from JAXB 1.0 to JAXB 2.0. First, we'll need to get a working implementation of JAXB 2.0. I recommend Sun's reference implementation which can be downloaded here (at the time I was writing this post, version 2.1.6 was the latest one). Just follow the instructions in that page to install it correctly and notice the bin subdirectory containing some scripts, including "xjc.bat" (for Windows; "xjc.sh" for Unix). This is the script supplied to execute JAXB 2.0 compilation. The trick here is to embed it in JDeveloper as an "External Tool". I'll show you how to do that step-by-step:
- Click the menu item "Tools -> External Tools..."
- Press the "New..." button to start the "Create External Tool" wizard
- Select "External Program" as the "Tool Type" and press "Next"
- Fill the 3 displayed fields as follows:
- Program Executable:
full path to the script "xjc.bat" which sould be <Sun_JAXB_2.1.6_install_dir>/bin/xjc.bat (or "xjc.sh" on Unix)
- Arguments:
-d "${project.first.sourcepath}" -p ${promptl:label=Target Package Name} "${file.path}".
Press button "Insert..." to see all macros available (i.e.: ${file.path}).
The arguments above will be passed to the script "xjc.bat". Execute it with no arguments in a command prompt to see a help on all possible arguments. The default is to compile a XML Schema but you can use -dtd to compile a DTD instead, although it's an experimental feature.
- Run Directory:
<Sun_JAXB_2.1.6_install_dir>/bin
- Press "Next" to advance to "Display" step and fill the 3 fields as you like. I suggest the following:
- Caption for Menu Items:
Compile XML Schema with JAXB 2.0
- ToolTip Text:
Compile a XML Schema with JAXB 2.0 Reference Implementation by Sun Microsystems
- ToolTip Text:
ide.fileicon:<SUN_JAXB_2.1.6_install_dir>/bin/xjc.bat
- Press "Next" to advance to "Integration" step where I recommend selecting "Tools Menu" and "Navigator Context Menu"
- Press "Next" to advance to the final step "Availability". Here, I recommend choosing the option "When Specific File Types are Selected" and then move only the item "XML Schema Type" from list "Available Types" to list "Selected Types"
- Press "Finish" and done!
Now we have the same built-in "JAXB Compilation" functionality described before but now using Sun's JAXB 2.1.6. So, let's repeat the same test case using our new tool. First, create a new empty project called "JAXB 2.0" also adding only "XML" to its technology scope. We'll need to create a JAXB 2.0 library and add it to the project:  The important here is to add the following archives, located in directory <Sun_JAXB_2.0_install_dir>/lib, to the library's class path: jaxb-api.jar, jaxb-impl.jar and jsr173_1.0_api.jar. Now just copy files "shiporder.xsd" and "testorder.xml" from project "JAXB 1.0" to this new project's root directory. Also be sure that the sources directory configured for the project exists and, if it doesn't, create it manually. That's needed because Sun's JAXB 2.1.6 compiler won't create its output directory automatically and the process will fail if that directory doesn't exist. Finally, select file "shiporder.xsd" in the Applications Navigator and execute our newly created menu item "Tools -> Compile XML Schema with JAXB 2.0" Define "test.jaxb2.shiporder" as the "Target Package Name" when prompted. After execution, you should see the following output:  Just click the "Refresh" button on the Applications Navigator and the new package "test.jaxb2.shiporder" will appear. At this point we can already make a simple comparison:  As you can see, instead of generating 16 interfaces, 15 classes and 1 property file, JAXB 2.0 generated only 4 classes! And like it was not enough, if you look inside those 4 classes you'll notice that they are all very simple POJOs!!! Take class "Shiporder.java" for example:
//
// This file was generated by the JavaTM Architecture for XML Binding(JAXB) Reference Implementation, v2.1.5-b01-fcs
// See <a href="http://java.sun.com/xml/jaxb">http://java.sun.com/xml/jaxb</a>
// Any modifications to this file will be lost upon recompilation of the source schema.
// Generated on: 2008.01.09 at 12:41:26 PM BRST
//
package test.jaxb2.shiporder;
import java.util.ArrayList;
import java.util.List;
import javax.xml.bind.annotation.XmlAccessType;
import javax.xml.bind.annotation.XmlAccessorType;
import javax.xml.bind.annotation.XmlAttribute;
import javax.xml.bind.annotation.XmlElement;
import javax.xml.bind.annotation.XmlRootElement;
import javax.xml.bind.annotation.XmlType;
/**
* <p>Java class for anonymous complex type.
*
* <p>The following schema fragment specifies the expected content contained within this class.
*
* <pre>
* <complexType>
* <complexContent>
* <restriction base="{http://www.w3.org/2001/XMLSchema}anyType">
* <sequence>
* <element ref="{}orderperson"/>
* <element ref="{}shipto"/>
* <element ref="{}item" maxOccurs="unbounded"/>
* </sequence>
* <attribute ref="{}orderid use="required""/>
* </restriction>
* </complexContent>
* </complexType>
* </pre>
*
*
*/
@XmlAccessorType(XmlAccessType.FIELD)
@XmlType(name = "", propOrder = {
"orderperson",
"shipto",
"item"
})
@XmlRootElement(name = "shiporder")
public class Shiporder {
@XmlElement(required = true)
protected String orderperson;
@XmlElement(required = true)
protected Shipto shipto;
@XmlElement(required = true)
protected List<Item> item;
@XmlAttribute(required = true)
protected String orderid;
/**
* Gets the value of the orderperson property.
*
* @return
* possible object is
* {@link String }
*
*/
public String getOrderperson() {
return orderperson;
}
/**
* Sets the value of the orderperson property.
*
* @param value
* allowed object is
* {@link String }
*
*/
public void setOrderperson(String value) {
this.orderperson = value;
}
/**
* Gets the value of the shipto property.
*
* @return
* possible object is
* {@link Shipto }
*
*/
public Shipto getShipto() {
return shipto;
}
/**
* Sets the value of the shipto property.
*
* @param value
* allowed object is
* {@link Shipto }
*
*/
public void setShipto(Shipto value) {
this.shipto = value;
}
/**
* Gets the value of the item property.
*
* <p>
* This accessor method returns a reference to the live list,
* not a snapshot. Therefore any modification you make to the
* returned list will be present inside the JAXB object.
* This is why there is not a <CODE>set</CODE> method for the item property.
*
* <p>
* For example, to add a new item, do as follows:
* <pre>
* getItem().add(newItem);
* </pre>
*
*
* <p>
* Objects of the following type(s) are allowed in the list
* {@link Item }
*
*
*/
public List<Item> getItem() {
if (item == null) {
item = new ArrayList<Item>();
}
return this.item;
}
/**
* Gets the value of the orderid property.
*
* @return
* possible object is
* {@link String }
*
*/
public String getOrderid() {
return orderid;
}
/**
* Sets the value of the orderid property.
*
* @param value
* allowed object is
* {@link String }
*
*/
public void setOrderid(String value) {
this.orderid = value;
}
}"public class Shiporder {". No interfaces being implemented, no classes being extended at all. Only a simple JavaBean with its attributes and their respective accessors. The "magic" here is done thanks to the annotations. They perform the actual mapping between the XML's structure defined by the compiled XML Schema and the classes derived from that compilation process. I think it's pretty obvious to see the huge advantages of JAXB 2.0 when compared to version 1.0. The compilation of a XML Schema produces much fewer classes and those classes are simply annotated POJOs. This certainly implies a much faster, lighter and easier to understand XML binding. Besides, there are some other details that makes JAXB 2.0 even more beneficial. Javadocs are automatically generated, it relies on cutting-edge XML parsing technology called "Streaming API for XML" which basically gives much more precise control over XML document processing. For further info on this, read " Oracle StAX Pull Parser Preview" and " JSR#173 homepage". Finally, as opposed to the known limitations of JDeveloper's built-in JAXB 1.0 compiler, Sun's JAXB 2.1.6 supports:
- Javadoc generation
- The key and keyref features of XML Schema
- The List and Union features of XML Schema
- SimpleType mapping to TypeSafe Enum class and IsSet property modifier
- XML Schema component "any" and substitution groups
- Customization of XML Schema to override the default binding of XML Schema components
- On-demand validation of content based on a given Schema
To run the same unmarshalling test, just create class " test.jaxb2.TestJAXB2" as follows: package test.jaxb2;
import java.io.File;
import javax.xml.bind.JAXBContext;
import javax.xml.bind.Unmarshaller;
import test.jaxb2.shiporder.Item;
import test.jaxb2.shiporder.Shiporder;
public class TestJAXB2 {
public static void main(String[] args) {
try {
JAXBContext context = JAXBContext.newInstance("test.jaxb2.shiporder");
Unmarshaller unmarshaller = context.createUnmarshaller();
Shiporder order = (Shiporder)unmarshaller.unmarshal(new File("testorder.xml"));
System.out.println("Items included in order #"+order.getOrderid()+" are:");
for (Item item : order.getItem()) {
System.out.println("\t:. "+item.getTitle()+" - "+
item.getQuantity()+" item(s) at $"+item.getPrice()+" each");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}This is slightly different from class " test.jaxb1.TestJAXB1" but, after running it, you should see exactly the same outcome:  Well, that's it. I think I've made my point. So good luck in your JAXB 2.0 adventures!
|
|
 Switch to new Dynamic Views
Switch to new Dynamic Views


, by Katherine Sierra (Author), Bert Bates (Author)*




























